Weakly Supervised Video Salient Object Detection via Point Supervision
Shuyong Gao, Haozhe Xing, Wei Zhang, Yan Wang, Qianyu Guo, Wenqiang Zhang
Proceedings of the 30th ACM International Conference on Multimedia (ACMMM 2022) (CCF A)
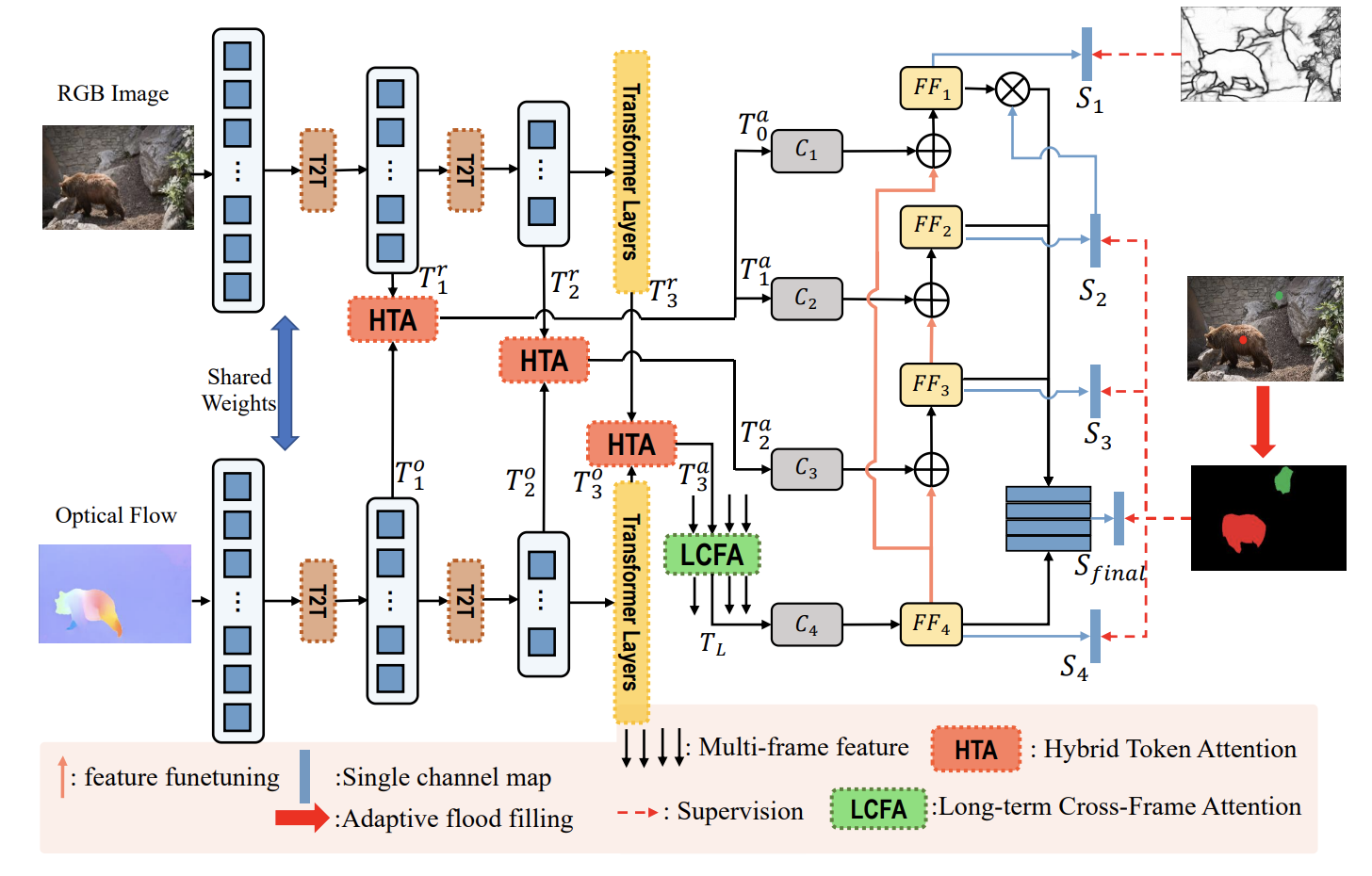
Video salient object detection models trained on pixel-wise dense annotation have achieved excellent performance, yet obtaining pixel-by-pixel annotated datasets is laborious. Several works attempt to use scribble annotations to mitigate this problem, but point supervision as a more labor-saving annotation method (even the most labor-saving method among manual annotation methods for dense prediction), has not been explored. In this paper, we propose a strong baseline model based on point supervision. To infer saliency maps with temporal information, we mine inter-frame complementary information from short-term and long-term perspectives, respectively. Specifically, we propose a hybrid token attention module, which mixes optical flow and image information from orthogonal directions, adaptively highlighting critical optical flow information (channel dimension) and critical token information (spatial dimension). To exploit long-term cues, we develop the Long-term Cross-Frame Attention module (LCFA), which assists the current frame in inferring salient objects based on multi-frame tokens. Furthermore, we label two point-supervised datasets, P-DAVIS and P-DAVSOD, by relabeling the DAVIS and the DAVSOD dataset. Experiments on the six benchmark datasets illustrate our method outperforms the previous state-of-the-art weakly supervised methods and even is comparable with some fully supervised approaches. Source code and datasets are available.