Dual Cross-Attention for Video Object Segmentation via Uncertainty Refinement
Jiahao Hong, Wei Zhang, Zhiwei Feng, Wenqiang Zhang
IEEE Transactions on Multimedia (CCF B)
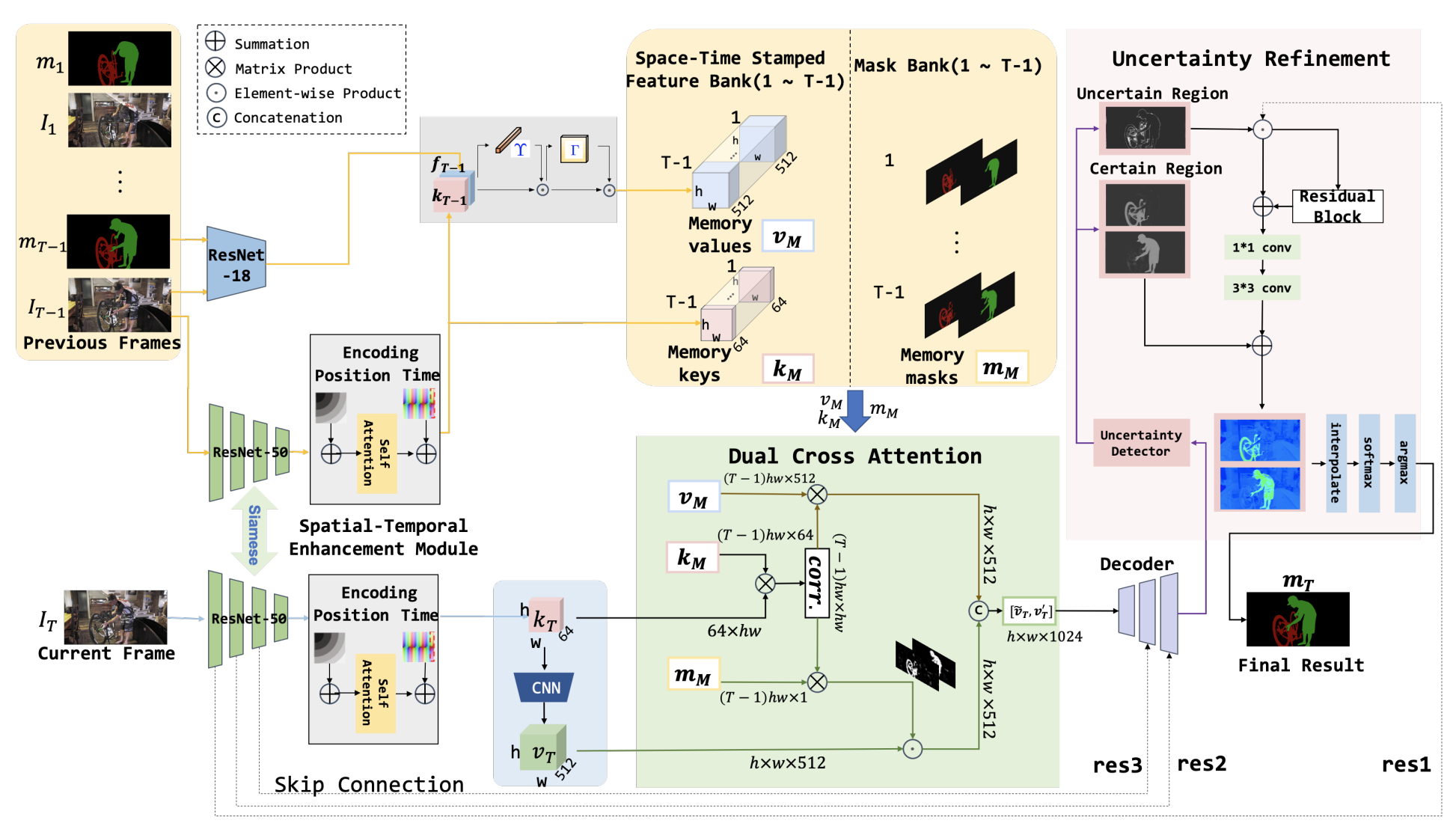
In this paper, we propose a novel approach to video object segmentation where dual streams consisting of a shared network and a special network are designed to constitute the feature memory of history frames. Cues of spatial position and time stamp are explicitly explored to learn the context for each frame in the video sequence. Self-attention and cross-attention are simultaneously exploited to extract more powerful features for segmentation. In contrast to STM and its variants, the proposed dual cross-attention performs in both appearance space and semantic space such that the derived features are more distinctive and then robust to similar overlapping objects. During decoding for segmentation, a local refinement technique is designed for the uncertain boundaries to obtain more precise and smooth object contours. Experimental results on the challenging benchmark datasets DAVIS-2016, DAVIS-2017, and YouTube-VOS demonstrate the effectiveness of our proposed approach to video object segmentation.