A large-scale empirical study of commit message generation: models, datasets and evaluation
Wei Tao, Yanlin Wang, Ensheng Shi, Lun Du, Shi Han, Hongyu Zhang, Dongmei Zhang, Wenqiang Zhang
Empirical Software Engineering (SCI Q2)
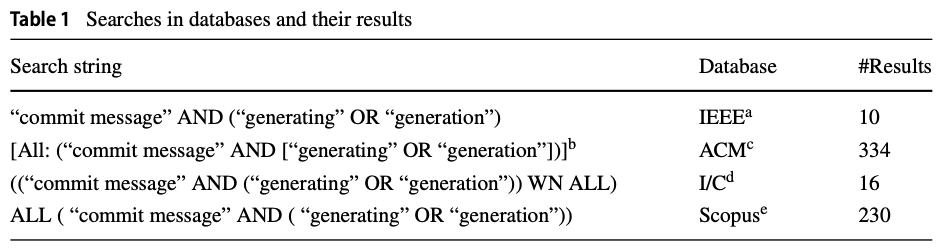
Commit messages are natural language descriptions of code changes, which are important for program understanding and maintenance. However, writing commit messages manually is time-consuming and laborious, especially when the code is updated frequently. Various approaches utilizing generation or retrieval techniques have been proposed to automatically generate commit messages. To achieve a better understanding of how the existing approaches perform in solving this problem, this paper conducts a systematic and in-depth analysis of the state-of-the-art models and datasets. We find that: (1) Different variants of the BLEU metric used in previous works affect the evaluation. (2) Most datasets are crawled only from Java repositories while repositories in other programming languages are not sufficiently explored. (3) Dataset splitting strategies can influence the performance of existing models by a large margin. (4) For pre-trained models, fune-tuning with different multi-programming-language combinations can influence their performance. Based on these findings, we collect a large-scale, information-rich, M ulti-language C ommit M essage D ataset (MCMD). Using MCMD, we conduct extensive experiments under different experiment settings including splitting strategies and multi-programming-language combinations. Furthermore, we provide suggestions for comprehensively evaluating commit message generation models and discuss possible future research directions. We believe our work can help practitioners and researchers better evaluate and select models for automatic commit message generation.